前言
本文翻译自 Sean McQuillan 的 Kotlin coroutines 入门系列。看了他的三篇文章,真正了解了协程出现的意义,它能帮开发者解决的问题,并掌握了它的基本用法。
原文地址:
- Coroutines on Android (part I): Getting the background
- Coroutines on Android (part II): Getting started
- Coroutines On Android (part III): Real work
协程可以做什么?
对于 Android 开发者来说,我们可以将协程运用在以下两个场景:
- 耗时任务:我们不应该在主线程做耗时操作。
- 主线程安全:我们可以在主线程中调用
suspend函数来执行一些操作而不阻塞主线程。
耗时任务 - Callback 实现
我们都知道不论是请求网络还是读取数据库都是耗时任务,我们不能在主线程去执行这些耗时操作。现在的手机 CPU 频率都是很高的,Pixel 2 的单核 CPU 周期小于 0.0000000004 秒(0.4纳秒),而一次网络请求大约是 0.4 秒(400 毫秒)。可以这么说,一眨眼功夫可以完成一次网络请求,但同时 CPU 已经执行了 10 亿多次。
Android 平台,主线程是 UI 线程,主要负责 View 的绘制(16 ms)和响应用户操作。如果我们在主线程做耗时操作,就会阻塞主线程,造成 View 不能及时刷新,不能及时响应用户操作,从而影响用户体验。
为了解决以上问题,我们一般使用 Callbacks 的方式。举个例子:
class ViewModel: ViewModel() {
fun fetchDocs() {
get("developer.android.com") { result ->
show(result)
}
}
}
尽管 get() 函数是被主线程调用的,但它的实现肯定是要在其他线程完成网络请求的。当结果返回时,Callback 又会在主线程被调用,来将结果显示到 UI 上。
耗时任务 - 协程实现
协程可以简化异步代码,用协程我们可以更方便地重写上面的例子:
// Dispatchers.Main
suspend fun fetchDocs() {
// Dispatchers.IO
val result = get("developer.android.com")
// Dispatchers.Main
show(result)
}
// look at this in the next section
suspend fun get(url: String) = withContext(Dispatchers.IO){/*...*/}
与普通函数相比,协程添加了 suspend 和 resume 两种操作。这两个操作一起完成了 Callback 的工作,但更优雅,就像是用同步代码完成了异步操作。
suspend:挂起当前协程,保存所有的本地变量;resume:恢复已经挂起的协程,从它暂停的地方继续执行。
suspend是 Kotlin 的一个关键字。被suspend标记的函数,只能在suspend函数内被调用。我们可以使用协程提供的launch和async从主线程启动一个协程来执行suspend函数。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
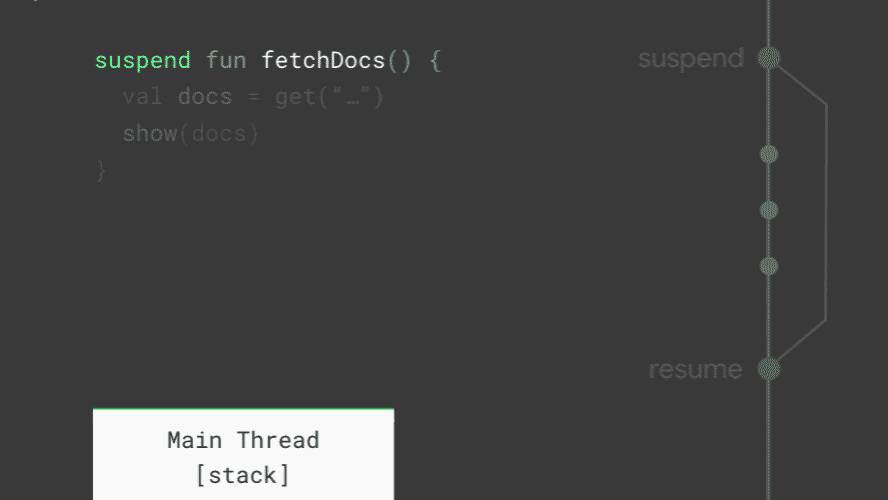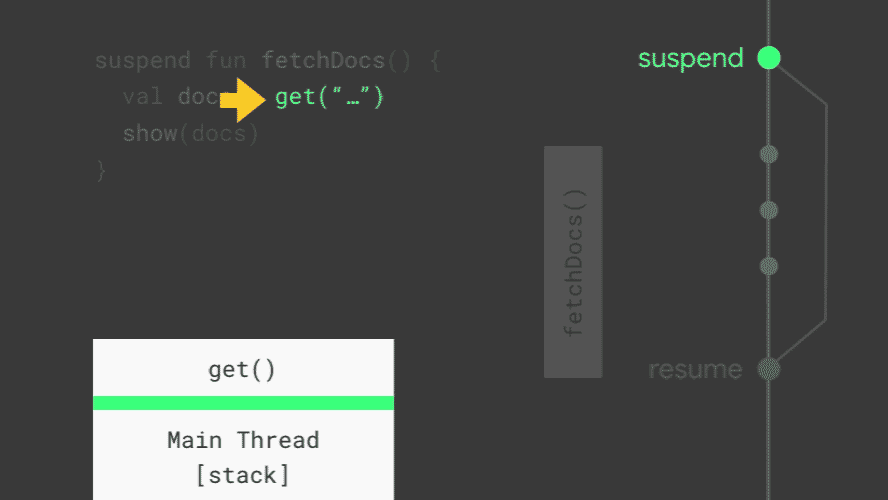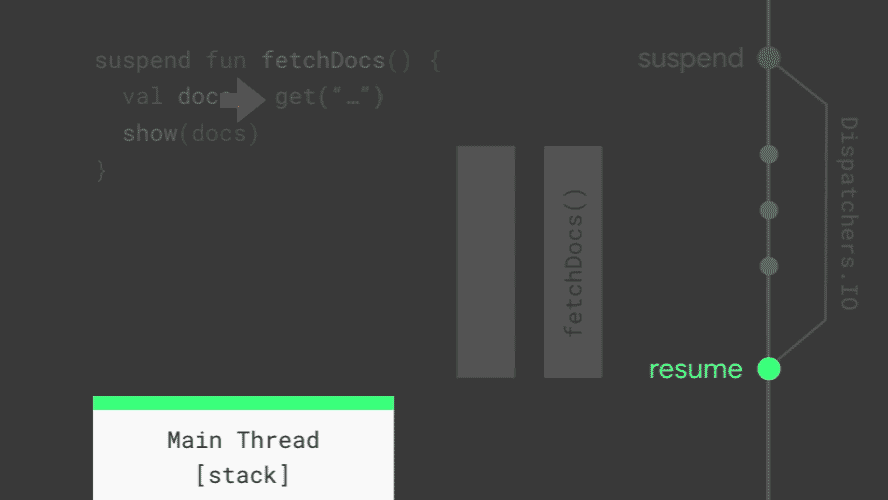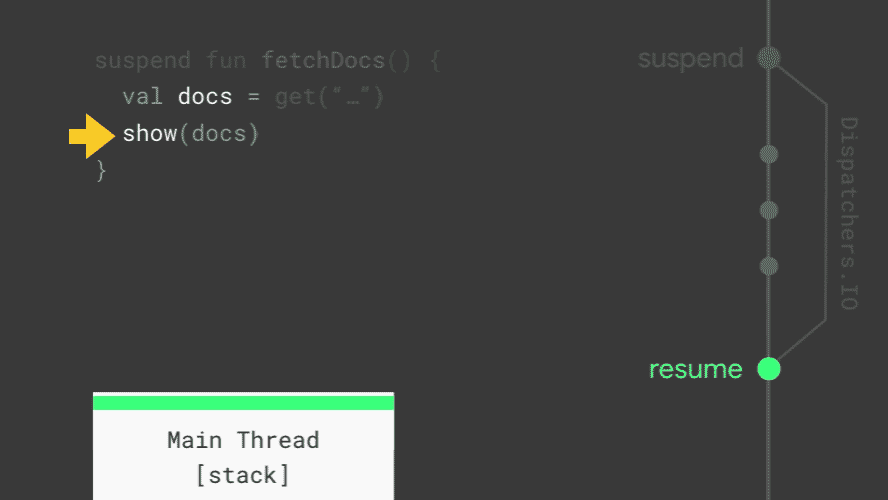
如动画所示,get() 函数在执行前会挂起(suspend)当前的协程,它内部依旧是通过 IO 线程(Dispatchers.IO)来执行网络请求。当请求完成时,它不是通过 Callback 的方式,而是恢复(resume)已经挂起的协程继续执行 show(result) 函数。任何一个协程被挂起时,当前的栈信息都会被复制并保存,以便在恢复时使用。当所有的协程都被挂起时,主线程不会被阻塞,仍然可以更新 UI 和响应用户操作。由此可见,协程为我们提供了一种异步操作的简单实现方式。
主线程安全
使用 Kotlin 协程的一个原则是:我们应该保证我们写的 suspend 函数是主线程安全的,也就是可以在任何线程中调用它,而不用去让调用者手动切换线程。
需要注意的是:**suspend 函数一般是运行在主线程中的,suspend 不是意味着运行的子线程。也就是说,我们需要在 suspend 内部指定该函数执行的线程,如不指定,它默认运行在调用者的线程。**
如果不是执行耗时任务,我们可以使用 Dispatchers.Main.immediate 来启动一个协程,下一次 UI 刷新时就会将结果显示到 UI 上。
所有的 Kotlin协程都必须运行在一个 Dispatcher 中,它提供了以下几种 Dispatcher 来运行协程。
| Dispatchers | 用途 | 使用场景 |
|---|---|---|
| Dispatchers.Main | 主线程、UI交互、执行轻量任务 | Call suspend functions, Call UI functions, Update LiveData |
| Dispatchers.IO | 网络请求、文件访问 | Database, Reading/writing files, Networking |
| Dispatchers.Default | CPU密集型任务 | Sorting a list, Parsing JSON, DiffUtils |
| Dispatchers.Unconfined | 不限制任何指定线程 | 总是使用第一个可用线程 |
完整的 get() 函数如下所示:
// Dispatchers.Main
suspend fun fetchDocs() {
// Dispatchers.Main
val result = get("developer.android.com")
// Dispatchers.Main
show(result)
}
// Dispatchers.Main
suspend fun get(url: String) =
// Dispatchers.IO
withContext(Dispatchers.IO) {
// Dispatchers.IO
/* perform blocking network IO here */
}
// Dispatchers.Main
使用协程我们可以自由控制代码运行的线程,withContext() 为我们提供了类似编写同步代码的方式来实现异步编程。如上面提到的:我们应尽量使用 withContext 确保每个函数都是线程安全的,不要让调用者关心要在哪个线程才能调用该函数。 上面的例子中,fetchDocs 运行在主线程,而 get() 运行在子线程,由于协程的 挂起/恢复 机制,当 withContext 返回时,当前协程会恢复执行。
在性能方面,withContext 跟 Callbacks 或 RxJava 不相上下。所以我们不用担心性能问题,相信官方也会持续优化。
结构化并发(Structured concurrency)
协程相比于线程来说,它是很轻量的。我们可以启动上百上千个协程,但无法启动这么多的线程。虽然协程很轻量,但它们的实际进行的任务可能是耗时的,比如用于读取数据库、请求网络或读写文件的协程。因此,我们仍需要维护好这些协程的完成和取消,否则可能发生任务泄露,这比内存泄漏更严重,因为任务可能浪费 CPU、磁盘或网络资源。
手动管理成百上千个协程是很困难的,为了避免协程泄露,Kotlin 提供了 结构化并发 来帮助我们更方便地追踪所有运行中的协程。在 Android 开发过程中,我们可以用它来完成以下三件事:
- 取消 不再需要的任务
- 追踪 所有运行中的任务
- 接收协程的 异常
取消限定作用域内的任务(Cancel work with scopes)
Kotlin 协程必须运行在 CoroutineScope 中,CoroutineScope 可以追踪所有运行中和已挂起的协程,不像上文提到的 Dispatchers,它只是保证对所有的协程的追踪,而不会真正地执行它们。因此为了确保所有的协程都能被追踪到,我们不能在 CoroutineScope 外启动一个新的协程。同时我们可以使用 CoroutineScope 来取消在它内部启动的所有协程。
我们需要在普通函数中启动一个协程,才能调用 suspend 函数。协程提供了两种方式来启动一个新的协程。
大多数情况下,我们使用 launch 来启动一个新的协程。**launch 函数就像连接普通函数和协程的桥梁。**
scope.launch {
// This block starts a new coroutine
// "in" the scope.
//
// It can call suspend functions
fetchDocs()
}
launch 和 async 最大的不同就是它们处理异常的方式:launch 启动的协程在发生异常时会立刻抛出,并立刻取消所有协程;而 async 启动的协程,只有我们调用 await() 函数时才能得到内部的异常,若无异常会返回执行结果。
AndroidX Lifecycle KTX 为我们提供了 viewModelScope 来方便地在 ViewModel 中启动协程,并保持对它们的追踪。
class MyViewModel(): ViewModel() {
fun userNeedsDocs() {
// Start a new coroutine in a ViewModel
viewModelScope.launch {
fetchDocs()
}
}
}
我们可以在一个 CoroutineScope 中包含若干个 CoroutineScope,如果我们在一个协程中启动了另一个协程,其实它们最终都同属于一个最顶层的 CoroutineScope,也就是说我们可以通过取消最外层的协程来取消所有内部的协程。 如果我们取消一个已经挂起的协程,它会抛出一个异常 CancellationException。如果我们捕获并消费了这个异常,或者取消一个未挂起的协程,该协程会处于一个 半取消(semi-canceled)状态。viewModelScope 启动的协程会在 ViewModel 销毁(clear)时自动取消,所以即使我们其内部执行是一个死循环,也会被自动取消。
fun runForever() {
// start a new coroutine in the ViewModel
viewModelScope.launch {
// cancelled when the ViewModel is cleared
while(true) {
delay(1_000)
// do something every second
}
}
}
追踪进行中的任务(Keep track of work)
我们可以使用协程进行网络请求、读写数据库等耗时操作。但有时我们可能需要在一个协程中同时进行两个网络请求,这时我们需要再启动两个协程来共同工作。我们可以在任何一个 suspend 函数中使用 coroutineScope 或 supervisorScope 来启动更多的协程。
在一个协程中启动新的协程可能会造成潜在的任务泄露,因为调用者可能不知道我们内部的实现。好消息是,结构化并发可以保证:如果一个 suspend 函数返回了,那么它内部的所有代码都已经执行完毕。 这仍然是同步调用的影子。
举个例子:
suspend fun fetchTwoDocs() {
coroutineScope {
launch { fetchDoc(1) }
async { fetchDoc(2) }
}
}
如上所示:fetchTwoDocs() 内部通过 coroutineScope 又启动了两个协程来同时加载两个文档,一个方式是 launch,一种方式是 async。为了避免 fetchTwoDocs() 任务泄露,coroutineScope 会一直保持挂起状态,直到内部的所有协程都执行完毕,这时 fetchTwoDocs() 函数才会返回。

以上示例,我们同时启动了 1000 个协程来请求网络,loadLots() 内部的 coroutineScope 是 该函数调用者的 CoroutineScope 的子集,内部的 coroutineScope 会一直保持这 1000 个协程的追踪,只有当所有协程都执行完毕,loadLots() 函数才会返回。
coroutineScope 和 supervisorScope 可以让我们在任意 suspend 函数内安全启动协程,直到内部的所有协程都执行完毕,它们才会返回。此外,如果我们取消了外层的 scope,内部的子协程也会被取消。coroutineScope 和 supervisorScope 的区别是:只要 coroutineScope 内的任一协程执行失败,整个 scope 都会被取消,内部的其他子协程也会立刻被取消;而 supervisorScope 内的某一协程失败,不会取消其他的子协程。
接收协程执行失败抛出的异常(Signal errors when a coroutine fails)
和普通函数一样,协程在执行失败时也会抛出异常。suspend 函数内抛出的异常是会向上传递的,我们也可以使用 try/catch 语法或其他方式捕获异常。但是下面这种异常可能会丢失:
val unrelatedScope = MainScope()
// example of a lost error
suspend fun lostError() {
// async without structured concurrency
unrelatedScope.async {
throw InAsyncNoOneCanHearYou("except")
}
}
以上代码中,我们在一个不相关的限定作用域内启动了一个协程,它并不是结构化并发的。由于 async 函数启动的协程只有在调用 await() 时才会抛出异常,所以这个异常可能会丢失,它会被一直保存着直到我们调用 await()。
结构化并发可以保证当一个协程发生异常时,它的调用者或 scope 可以收到这个异常。
上面代码用结构化并发的方式改写如下:
suspend fun foundError() {
coroutineScope {
async {
throw StructuredConcurrencyWill("throw")
}
}
}
总结一下:
coroutineScope和supervisorScope是结构化并发的,可以追踪内部的所有协程,包括异常处理、任务取消等。GlobalScope不是结构化并发的,它是一个全局的 scope,跟 Application 同生命周期。
Kotlin Coroutines VS RxJava&RxAndroid
Kotlin Coroutines 与 RxJava&RxAndroid 都可以方便的帮我们进行异步编程,个人觉得它们在异步编程最大的区别是:Coroutines 的编写方式更像是同步调用,而 RxJava 是流式编程。但本质上,它们内部都是通过线程池来处理耗时任务。RxJava 的有很多个操作符可以辅助实现各式各样的需求,并能保证链式调用;Coroutines 是与 Kotlin 结合的最好异步编程方式,目前也有很多的官方支持,相信将来 Coroutines 会有很好的使用体验和执行性能。
Reference
- 【Official】Improve app performance with Kotlin coroutines
- 【Medium】Coroutines on Android (part I): Getting the background
- 【Medium】Coroutines on Android (part II): Getting started
- 【GitHub】Kotlin/kotlinx.coroutines
联系
我是 xiaobailong24,您可以通过以下平台找到我:

